MLeap Bundles
MLeap Bundles are a graph-based, portable file format for serializing and de-serializing:
- Machine learning data pipelines - any transformer-based data pipeline
- Algorithms (Regressions, Tree-Based models, Bayesian models, Neural Nets, Clustering)
Bundles make it very easy to share the results of your training pipeline, simply generate a bundle file and send it through email to a colleague or just view the metadata of your data pipeline and algorithm!
Bundles also make deployments simple: just export your bundle and load it into your Spark, Scikit-learn, or MLeap-based application.
Features of MLeap Bundles
- Serialize to a directory or a zip file
- Entirely JSON and Protobuf-based format
- Serialize as pure JSON, pure Protobuf, or mixed mode
- Highly extensible, including easy integration with new transformers
Common Format For Spark, Scikit-Learn, TensorFlow
MLeap provides a serialization format for common transformers that are found in Spark, Scikit and TF. For example, consider the Standard Scaler trasnformer (tf.random_normal_initializer in TensorFlow). It performs the same opperation on all three platforms so in theory can be serialized, deserialized and used interchangeably between them.
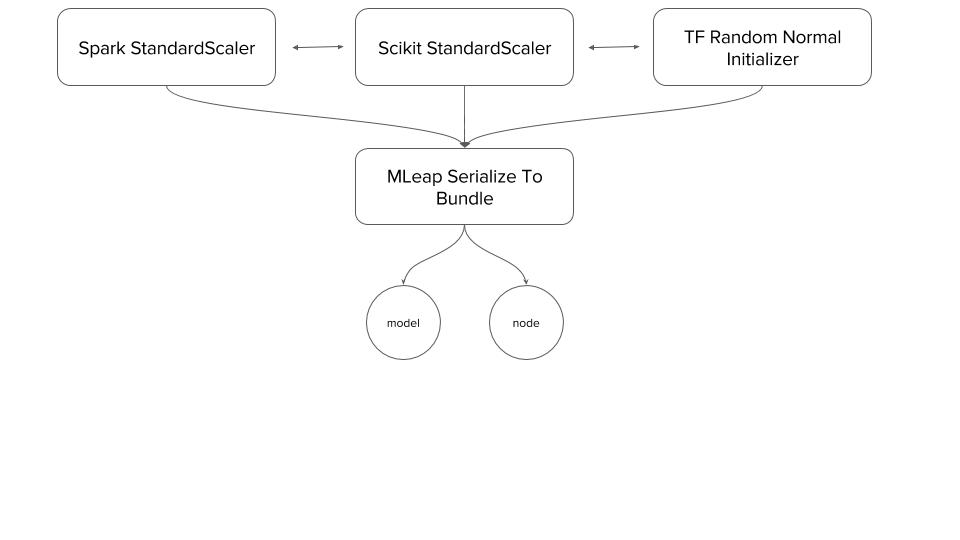
Bundle Structure
At its root directory, a bundle has a bundle.json file, which provides
basic meta data about the serialization of the bundle. It also has a
root/ directory, which contains the root transformer of the ML
pipeline. The root transformer can be any type of transformer supported
by MLeap, but is most commonly going to be a Pipeline transformer.
Let's take a look at an example MLeap Bundle. The pipeline consists of string indexing a set of categorical features, followed by one hot encoding them, assembling the results into a feature vector and finally executing a linear regression on the features. Here is what the bundle looks like:
├── bundle.json
└── root
├── linReg_7a946be681a8.node
│ ├── model.json
│ └── node.json
├── model.json
├── node.json
├── oneHot_4b815730d602.node
│ ├── model.json
│ └── node.json
├── strIdx_ac9c3f9c6d3a.node
│ ├── model.json
│ └── node.json
└── vecAssembler_9eb71026cd11.node
├── model.json
└── node.json
bundle.json
{
"uid": "7b4eaab4-7d84-4f52-9351-5de98f9d5d04",
"name": "pipeline_43ec54dff5b2",
"timestamp": "2017-09-03T17:41:25.206",
"format": "json",
"version": "0.21.0"
}
uidis a Java UUID that is automatically generated as a unique ID for the bundlenameis theuidof the root transformerformatis the serialization format used to serialize this bundleversionis a reference to the version of MLeap used to serialize the bundletimestampdefines when the bundle was serialized
model.json
For the pipeline:
{
"op": "pipeline",
"attributes": {
"nodes": {
"type": "list",
"string": ["strIdx_ac9c3f9c6d3a", "oneHot_4b815730d602", "vecAssembler_9eb71026cd11", "linReg_7a946be681a8"]
}
}
For the linear regression:
{
"op": "linear_regression",
"attributes": {
"coefficients": {
"double": [7274.194347379634, 4326.995162668048, 9341.604695180558, 1691.794448740186, 2162.2199731255423, 2342.150297286721, 0.18287261938061752],
"shape": {
"dimensions": [{
"size": 7,
"name": ""
}]
},
"type": "tensor"
},
"intercept": {
"double": 8085.6026142683095
}
}
opspecifies the operation to be executed, there is one op name for each transformer supported by MLeapattributescontains the values needed by the operation in order to execute
node.json
For the one hot encoder:
{
"name": "oneHot_4b815730d602",
"shape": {
"inputs": [{
"name": "fico_index",
"port": "input"
}],
"outputs": [{
"name": "fico",
"port": "output"
}]
}
}
namespecifies the name of the node in the execution graphshapespecifies the inputs and outputs of the node, and how they are to be used internally by the operation
In this case, the fico_index column is to be used as the input column
of the one hot encoder, and fico will be the result column.
MLeap Bundle Examples
Here are some examples of serialized bundle files. They are not meant to be useful pipelines, but rather to illustrate what these files actually look like. The pipelines were generated when running our Spark parity tests, which ensure that MLeap transformers and Spark transformers produce exactly the same outputs.
MLeap/Spark Parity Bundle Examples
NOTE: right click and "Save As...", Gitbook prevents directly clicking on the link.